
Last week we talked about normal distribution in your data. This week let’s kick the conversation off with non-normal distribution. There are a few different types of non-normal distribution, let’s take a look.
Skewed distribution
Skewed data is quite simply, a data distribution that is not symmetrical. Usually the longest tail points should point in the direction of the skew. Here’s what a skew looks like
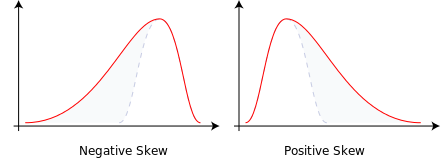 Skewness can be caused by any variations, but here are the most common causes.
Skewness can be caused by any variations, but here are the most common causes.
Natural Limits
Natural limits-these are the limits of sample size. The problem with natural limits is that these natural limits can bias the estimation of results and in some cases ensure that there can be no specific correlation between the sample and the data field.
Sorting
This is also known as artificial limits and it’s important to realize that limits are imposed by the person analyzing the data. Basically artificial limits set an arbitrary point for acceptable and not acceptable. Say you make 40 chairs and hour, your designer decides that any chair that doesn’t make a rating of 80 is unacceptable. That acceptable rating is completely arbitrary based on the designer’s standards.
Mixtures
Mixtures occur when data from different sources is expected to be the same and is different. Say you’re looking for error data from two cashiers Shift A credit card receipts and Shift B, cash receipts and the skew is not the same. You were expecting the error rate for each method to have a normal distribution and what you got showed something like this.
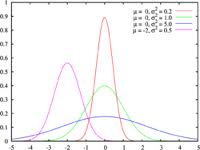
Next week we will pick up with a continuation of non-normal distributions. Until then, Happy analyzing
